I saw one forum post from 2015 achieving the same thing I am trying to accomplish:
I would like to set a rule for email addresses and/or email addresses with given aliases containing certain words/lettering or ‘first level domains’ as it is apparently called.
To my current knowledge having used eM client for the past year, the default junk filter is horrible and doesn’t catch much if any and currently all of my junk filtering is painstakingly done with custom rules I have to constantly write and update myself.
There needs to be more ways, better ways, to use this rule system.
I’m not familiar with the ins and outs beyond what’s basically shown to us in the rules config screen, but if anyone knows of ways to include special characters similar to html formatting for example adding a | or # so that a full domain is not required, that would be great.
The fact is, spammers and scammers are making new email addresses and whole new ‘second level domains’ constantly to keep up, but what doesn’t change is that they’re using the same few ‘first level domains’ like .icu or .xyz leaving the last option of filtering by words or phrases and that’s just tricky, emails are constantly being re-worded and depending on what words you want to use you’re likely going to have to add a lot of exceptions to be safe on top of that.
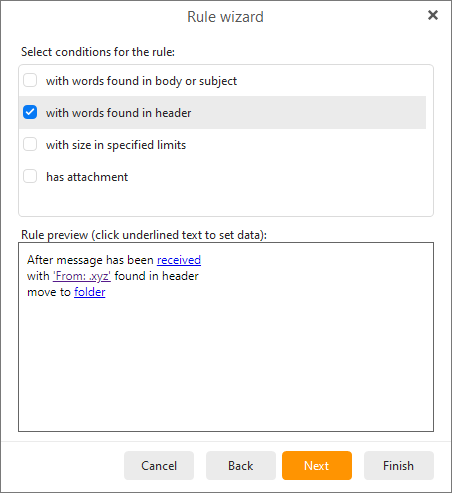
One rule I don’t yet know best how to use is ‘words found in header’ which says it has to use a word:word pairing… what information should I pay attention to for adding to rules and how would I best use this as a filter?
Help a guy out, open to suggestions and learning more about rule-making.
For supporting you it would be helpful to paste your rule here for giving you hints, how to improve it.
I have a hunch that you left out the last entry: stop procesing other rules. Therefore, following rules process these mails, too, which leads to the effect, that they survive.
Be aware that blocking *.fr blocks all mail from france.
This rule is much too fuzzy for my taste. Instead of filtering sender addresses you should think about checking for keywords and combinations like
After message has been received
from ‘*.fr’
and my name is not in the To field
and with ‘gros seins’ found in body
move to Junk E-mail
and mark as read
and stop processing other rules
Filtering header is a very sharp knife to detect detailed information to take account on. See following extract:
In this snippet you find X-Spam-Status: Yes which is a typical indicator that you do not want this email. Putting this in a header filter should move a lot of the crap directly to junk.
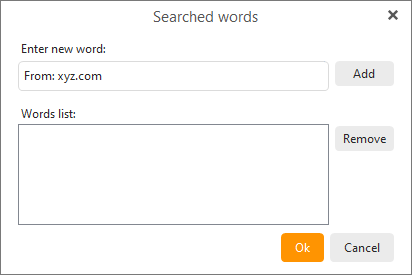
I just tried before both of your replies to add a ‘words in header’ rule which used from:’.xyz’ with no spaces or asterisks, but again, I still don’t know if the space which you both used is needed or if the asterisk which NoSi1 used is necessary or what the function of having asterisk in or out changes, hope to hear back again about that, will edit in the space now to be safe though.
Also I didn’t see X-Spam or spamassassin listed in my headers when opened in eM Client, is there something I’m missing?
After message has been received
with ‘from: .best’, ‘from: .bid’, ‘from: .club’, ‘from: .de’, ‘from: .ec’, ‘from: .host’, ‘from: .icu’, ‘from: .it’, ‘from: .online’, ‘from: .pro’, ‘from: .shop’, ‘from: .site’, ‘from: .us’, ‘from: .website’, ‘from: .xyz’, ‘from: .cn’ found in header
move to Junk E-mail
and stop processing other rules
except with (hidden for privacy) found in body or subject
or except with (hidden for privacy) found in header
I will take the asterisk info on board, thank you for explaining, though due to Gary’s response, I will avoid asterisks at present…
Are there any characters which can be used at the end of the previously used example .fr to state that this must be at the end and not at a random place like [email protected] or [email protected]?
Also, another question… inside a header, I see the from line being both name and address as follows: From: "Bye Bye Insects" <[email protected]>
Does a from: .xyz rule count the whole line or only what is within quotes or only what is within the open close arrow brackets? and furthermore, do I need to make my rules Case Sensitive or is it fine either way?
This is why I have it going to junk folder and not being trashed, since I know there may be things which mistakenly get caught.
This is also why I asked if I could make a rule for .de to be required at the end and not at random points.
As I previously mentioned that the whole header line was: From: "Bye Bye Insects" <[email protected]>
I am also curious whether the > symbol counts as a searchable character or if it is ignored as header formatting.
If it is included then I could adjust by putting the > at the end of my .de argument and then it would correctly find email addresses which must be [email protected] because inside the header it would appear as From: "anything anything" <[email protected]> and my rule would be from: .de>
It might be better for you to use the whole domain, so From: tastyclay.xyz. Would be so sad if a legitiamte user [email protected] tried to email you about the wallet he found in your trash last time you had the car cleaned.
Since tastyclay.xyz might get used for 100,000 spam emails in one day and then never get used, it would be rather pointless to filter one particular domain.
Also I’ve never gotten a legitimate email from any of these first level domains that I’m targeting so I believe they’re a pretty safe bet, obviously this is also why I’m not targeting domains that most people on earth use like .co, .com, .org.
I have however added an exception for when my name is specifically used so that those ones can be directly checked by myself.
I will try to add the > and see if that will work.
However I have sadly also noticed that at present my filter doesn’t appear to be filtering .xyz at all…
To double check again, are rules case sensitive? Do I need to use From: .xyz or does from: .xyz do the same thing?
Sure, but I’m not German or Italian or American, so at the least I’m not about to get any emails from .de or .it, and as for .us, I’ll have exception filters to ensure that only relevant and legitimate emails come through.
I’m not planning on flat blacklisting a whole country code without exceptions in place.